
Using Machine Learning to Identify Cyber Attacks
The Deflect platform is a free website security service defending civil society and human rights groups from digital attack. Currently, malicious traffic is identified on the Deflect network by Banjax, a system that uses handwritten rules to flag IPs that are behaving like attacking bots, so that they can be challenged or banned. While Banjax is successful at identifying the most common bruteforce cyber attacks, the approach of using a static set of rules to protect against the constantly evolving tools available to attackers is fundamentally limited. Over the past year, the Deflect Labs team has been working to develop a machine learning module to automatically identify malicious traffic on the Deflect platform, so that our mitigation efforts can keep pace with the methods of attack as these grow in complexity and sophistication.
In this report, we look at the performance of the Deflect Labs’ new anomaly detection tool, Baskerville, in identifying a selection of the attacks seen on the Deflect platform during the last year. Baskerville is designed to consume incoming batches of web logs (either live from a Kafka stream, or from Elasticsearch storage), group them into request sets by host website and IP, extract the browsing features of each request set, and make a prediction about whether the behaviour is normal or not. At its core, Baskerville currently uses the Scikit-Learn implementation of the Isolation Forest anomaly detection algorithm to conduct this classification, though the engine is agnostic to the choice of algorithm and any trained Scikit-Learn classifier can be used in its place. This model is trained on normal web traffic data from the Deflect platform, and evaluated using a suite of offline tools incorporated in the Baskerville module. Baskerville has been designed in such a way that once the performance of the model is sufficiently strong, it can be used for real-time attack alerting and mitigation on the Deflect platform.
To showcase the current capabilities of the Baskerville module, we have replayed the attacks covered in the 2018 Deflect Labs report: Attacks Against Vietnamese Civil Society, passing the web logs from these incidents through the processing and prediction engine. This report was chosen for replay because of the variety of attacks seen across its constituent incidents. There were eight attacks in total considered in this report, detailed in the table below.
| Date | Start (approx.) | Stop (approx.) | Target |
| 2018/04/17 | 08:00 | 10:00 | viettan.org |
| 2018/04/17 | 08:00 | 10:00 | baotiengdan.com |
| 2018/05/04 | 00:00 | 23:59 | viettan.org |
| 2018/05/09 | 10:00 | 12:30 | viettan.org |
| 2018/05/09 | 08:00 | 12:00 | baotiengdan.com |
| 2018/06/07 | 01:00 | 05:00 | baotiengdan.com |
| 2018/06/13 | 03:00 | 08:00 | baotiengdan.com |
| 2018/06/15 | 13:00 | 23:30 |
baotiengdan.com |
Table 1: Attack time periods covered in this report. The time period of each attack was determined by referencing the number of Deflect and Banjax logs recorded for each site, relative to the normal traffic volume.
How does it work?
Given one request from one IP, not much can be said about whether or not that user is acting suspiciously, and thus how likely it is that they are a malicious bot, as opposed to a genuine user. If we instead group together all the requests to a website made by one IP over time, we can begin to build up a more complete picture of the user’s browsing behaviour. We can then train an anomaly detection algorithm to identify any IPs that are behaving outside the scope of normal traffic.
The boxplots below illustrate how the behaviour during the Vietnamese attack time periods differs from that seen during an average fortnight of requests to the same sites. To describe the browsing behaviour, 17 features (detailed in the Baskerville documentation) have been extracted based on the request sets (note that the feature values are scaled relative to average distributions, and do not have a physical interpretation). In particular, it can be seen that these attack time periods stand out by having far fewer unique paths requested (unique_path_to_request_ratio), a shorter average path depth (path_depth_average), a smaller variance in the depth of paths requested (path_depth_variance), and a lower payload size (payload_size_log_average). By the ‘path depth’, we mean the number of slashes in the requested URL (so ‘website.com’ has a path depth of zero, and ‘website.com/page1/page2’ has a path depth of two), and by ‘payload size’ we mean the size of the request response in bytes.
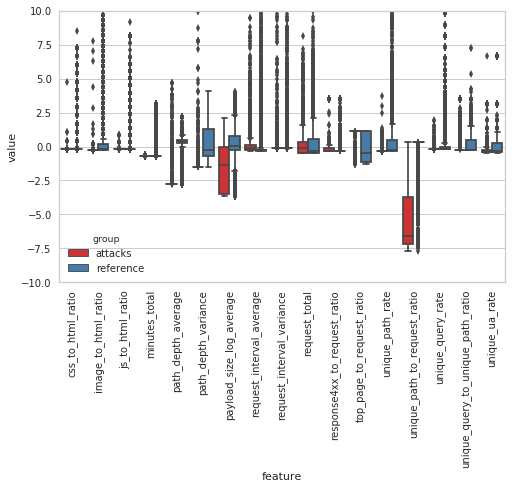
Figure 1: The distributions of the 17 scaled feature values during attack time periods (red) and non-attack time periods (blue). It can be seen that the feature distributions are notably different during the attack and non-attack periods.
The separation between the attack and non-attack request sets can be nicely visualised by projecting along the feature dimensions identified above. In the three-dimensional space defined by the average path depth, the average log of the payload size, and the unique path to request ratio, the request sets identified as malicious by Banjax (red) are clearly separated from those not identified as malicious (blue).
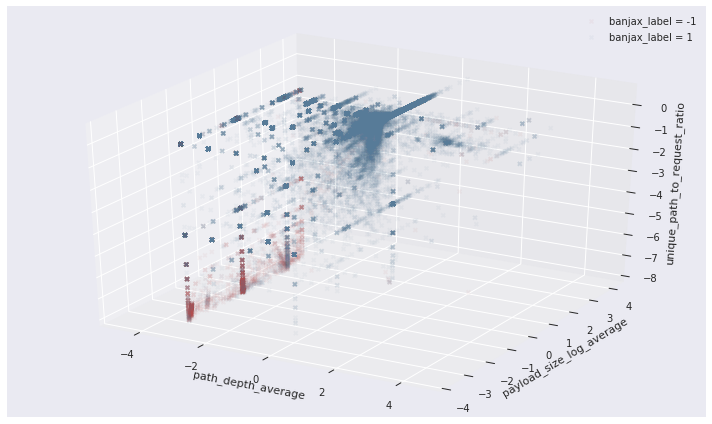
Figure 2: The distribution of request sets along three of the 17 feature dimensions for IPs identified as malicious (red) or benign (blue) by the existing banning module, Banjax. The features shown are the average path depth, the average log of the request payload size, and the ratio of unique paths to total requests, during each request set. The separation between the malicious (red) and benign (blue) IPs is evident along these dimensions.
Training a Model
A machine learning classifier enables us to more precisely define the differences between normal and abnormal behaviour, and predict the probability that a new request set comes from a genuine user. For this report, we chose to train an Isolation Forest; an algorithm that performs well on novelty detection problems, and scales for large datasets.
As an anomaly detection algorithm, the Isolation Forest took as training data all the traffic to the Vietnamese websites over a normal two-week period. To evaluate its performance, we created a testing dataset by partitioning out a selection of this data (assumed to represent benign traffic), and combining this with the set of all requests coming from IPs flagged by the Deflect platform’s current banning tool, Banjax (assumed to represent malicious traffic). There are a number of tunable parameters in the Isolation Forest algorithm, such as the number of trees in the forest, and the assumed contamination with anomalies of the training data. Using the testing data, we performed a gridsearch over these parameters to optimize the model’s accuracy.
Replaying the Attacks
The model chosen for use in this report has a precision of 0.90, a recall of 0.86, and a resultant f1 score of 0.88, when evaluated on the testing dataset formulated from the Vietnamese website traffic, described above. If we take the Banjax bans as absolute truth (which is almost certainly not the case), this means that 90% of the IPs predicted as anomalous by Baskerville were also flagged by Banjax as malicious, and that 88% of all the IPs flagged by Banjax as malicious were also identified as anomalous by Baskerville, across the attacks considered in the Vietnamese report. This is demonstrated visually in the graph below, which shows the overlap between the Banjax flag and the Baskerville prediction (-1 indicates malicious, and +1 indicates benign). It can be seen that Baskerville identifies almost all of the IPs picked up by Banjax, and additionally flags a fraction of the IPs not banned by Banjax.
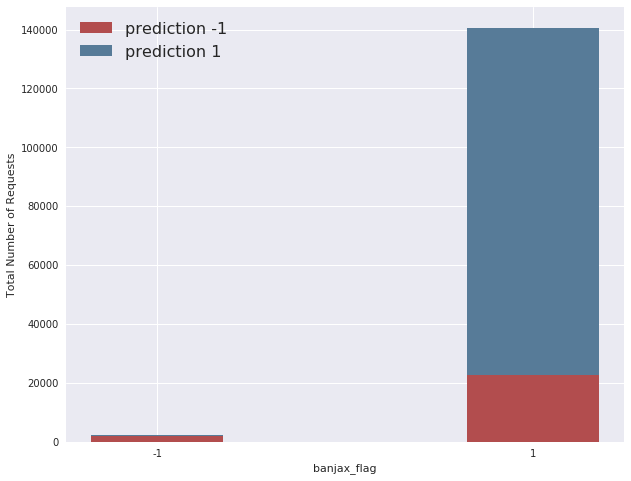
Figure 3: The overlap between the Banjax results (x-axis) and the Baskerville prediction results (colouring). Where the Banjax flag is -1 and the prediction colour is red, both Banjax and Baskerville agree that the request set is malicious. Where the Banjax flag is +1 and the prediction colour is blue, both modules agree that the request set is benign. The small slice of blue where the Banjax flag is -1, and the larger red slice where the Banjax flag is +1, indicate request sets about which the modules do not agree.
The performance of the model can be broken down across the different attack time periods. The grouped bar chart below compares the number of Banjax bans (red) to the number of Baskerville anomalies (green). In general, Baskerville identifies a much greater number of request sets as being malicious than Banjax does, with the exception of the 17th April attack, for which Banjax picked up slightly more IPs than Baskerville. The difference between the two mitigation systems is particularly pronounced on the 13th and 15th June attacks, for which Banjax scarcely identified any malicious IPs at all, but Baskerville identified a high proportion of malicious IPs.
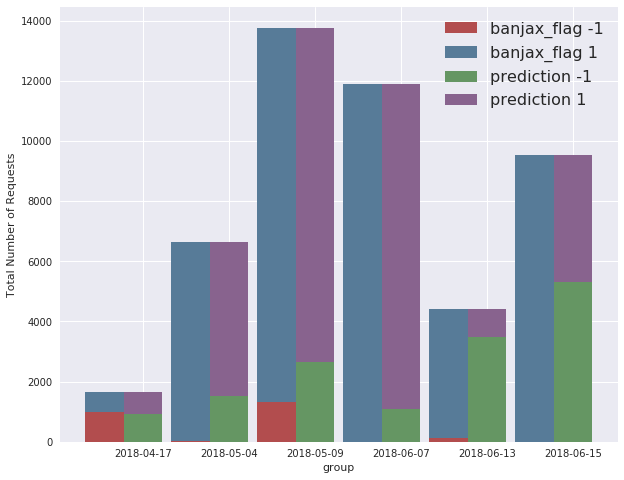
Figure 4: The verdicts of Banjax (left columns) and Baskerville (right columns) across the 6 attack periods. The red/green components show the number of request sets that Banjax/Baskerville labelled as malicious, while the blue/purple components show the number that they labelled as benign. The fact that the green bars are almost everywhere higher than the red bars indicates that Baskerville picks up more traffic as malicious than does Banjax.
This analysis highlights the issue of model validation. It can be seen that Baskerville is picking up more request sets as being malicious than Banjax, but does this indicate that Baskerville is too sensitive to anomalous behaviour, or that Baskerville is outperforming Banjax? In order to say for sure, and properly evaluate Baskerville’s performance, a large testing set of labelled data is needed.
If we look at the mean feature values across the different attacks, it can be seen that the 13th and 15th June attacks (the red and blue dots, respectively, in the figure below) stand out from the normal traffic in that they have a much lower than normal average path depth (path_depth_average), and a much higher than normal 400-code response rate (response4xx_to_request_ratio), which may have contributed to Baskerville identifying a large proportion of their constituent request sets as malicious. Since a low average path depth (e.g. lots of requests made to ‘/’) and a high 400 response code rate (e.g. lots of requests to non-existent pages) are indicative of an IP behaving maliciously, this may suggest that Baskerville’s predictions were valid in these cases. But more labelled data is required for us to be certain about this evaluation.
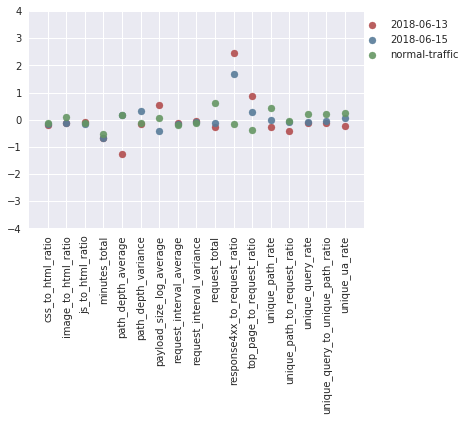
Figure 5: Breakdown of the mean feature values during the two attack periods (red, blue) for which Baskerville identified a high proportion of malicious IPs, but Banjax did not. These are compared to the mean feature values during a normal two-week period (green).
Putting Baskerville into Action
Replaying the Vietnamese attacks demonstrates that it is possible for the Baskerville engine to identify cyber attacks on the Deflect platform in real time. While Banjax mitigates attacks using a set of static human-written rules describing what abnormal traffic looks like, by comprehensively describing how normal traffic behaves, the Baskerville classifier is able to identify new types of malicious behaviour that have never been seen before.
Although the performance of the Isolation Forest in identifying the Vietnamese attacks is promising, we would require a higher level of accuracy before the Baskerville engine is used to automatically ban IPs from accessing Deflect websites. The model’s accuracy can be improved by increasing the amount of data it is trained on, and by performing additional feature engineering and parameter tuning. However, to accurately assess its skill, we require a large set of labelled testing data, more complete than what is offered by Banjax logs. To this end, we propose to first deploy Baskerville in a developmental stage, during which IPs that are suspected to be malicious will be served a Captcha challenge rather than being absolutely banned. The results of these challenges can be added to the corpus of labelled data, providing feedback on Baskerville’s performance.
In addition to the applications of Baskerville for attack mitigation on the Deflect platform, by grouping incoming logs by host and IP into request sets, and extracting features from these request sets, we have created a new way to visualise and analyse attacks after they occur. We can compare attacks not just by the IPs involved, but also by the type of behaviour displayed. This opens up new possibilities for connecting disparate attacks, and investigating the agents behind them.
Where Next?
The proposed future of Deflect monitoring is the Deflect Labs Information Sharing and Analysis Centre (DL-ISAC). The underlying idea behind this project, summarised in the schematic below, is to split the Baskerville engine into separate User Module and Clearinghouse components (dealing with log processing and model development, respectively), to enable a complete separation of personal data from the centralised modelling. Users would process their own web logs locally, and send off feature vectors (devoid of IP and host site details) to receive a prediction. This allows threat-sharing without compromising personally identifiable information (PII). In addition, this separation would enable the adoption of the DL-ISAC by a much broader range of clients than the Deflect-hosted websites currently being served. Increasing the user base of this software will also increase the amount of browsing data we are able to collect, and thus the strength of the models we are able to train.
Baskerville is an open-source project, with its first release scheduled next quarter. We hope this will represent the first step towards enabling a new era of crowd-sourced threat information sharing and mitigation, empowering internet users to keep their content online in an increasingly hostile web environment.
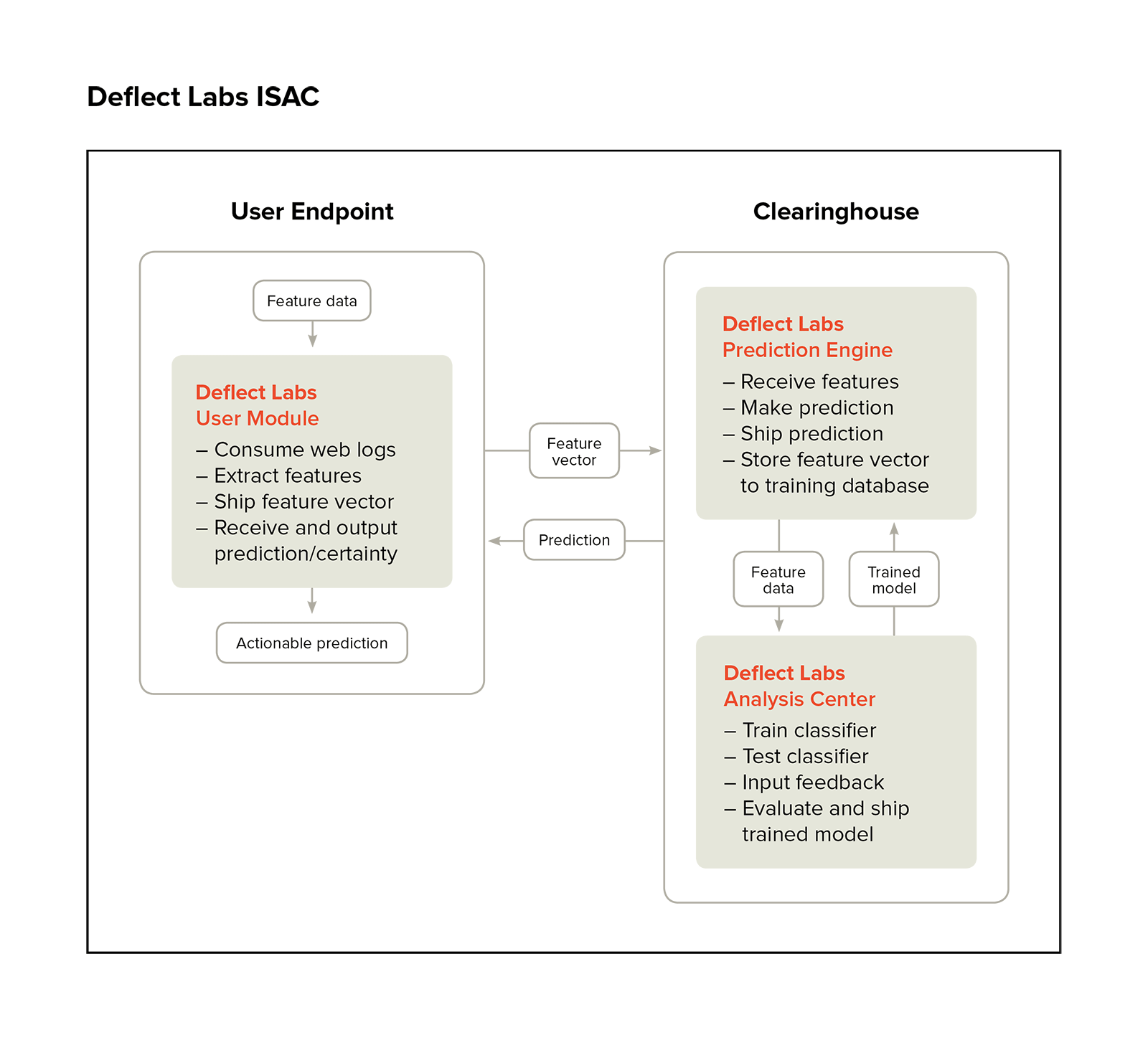
Figure 6: A schematic of the proposed structure of the DL-ISAC. The infrastructure is split into a log-processing user endpoint, and a central clearinghouse for prediction, analysis, and model development.
A Final Word: Bias in AI
In all applications of machine learning and AI, it is important to consider sources of algorithmic bias, and how marginalised users could be unintentionally discriminated against by the system. In the context of web traffic, we must take into account variations in browsing behaviour across different subgroups of valid, non-bot internet users, and ensure that Baskerville does not penalise underrepresented populations. For instance, checks should be put in place to prevent disadvantaged users with slower internet connections from being banned because their request behaviour differs from those users that benefit from high-speed internet. The Deflect Labs team is committed to prioritising these considerations in the future development of the DL-ISAC.