Deflect
Baskerville
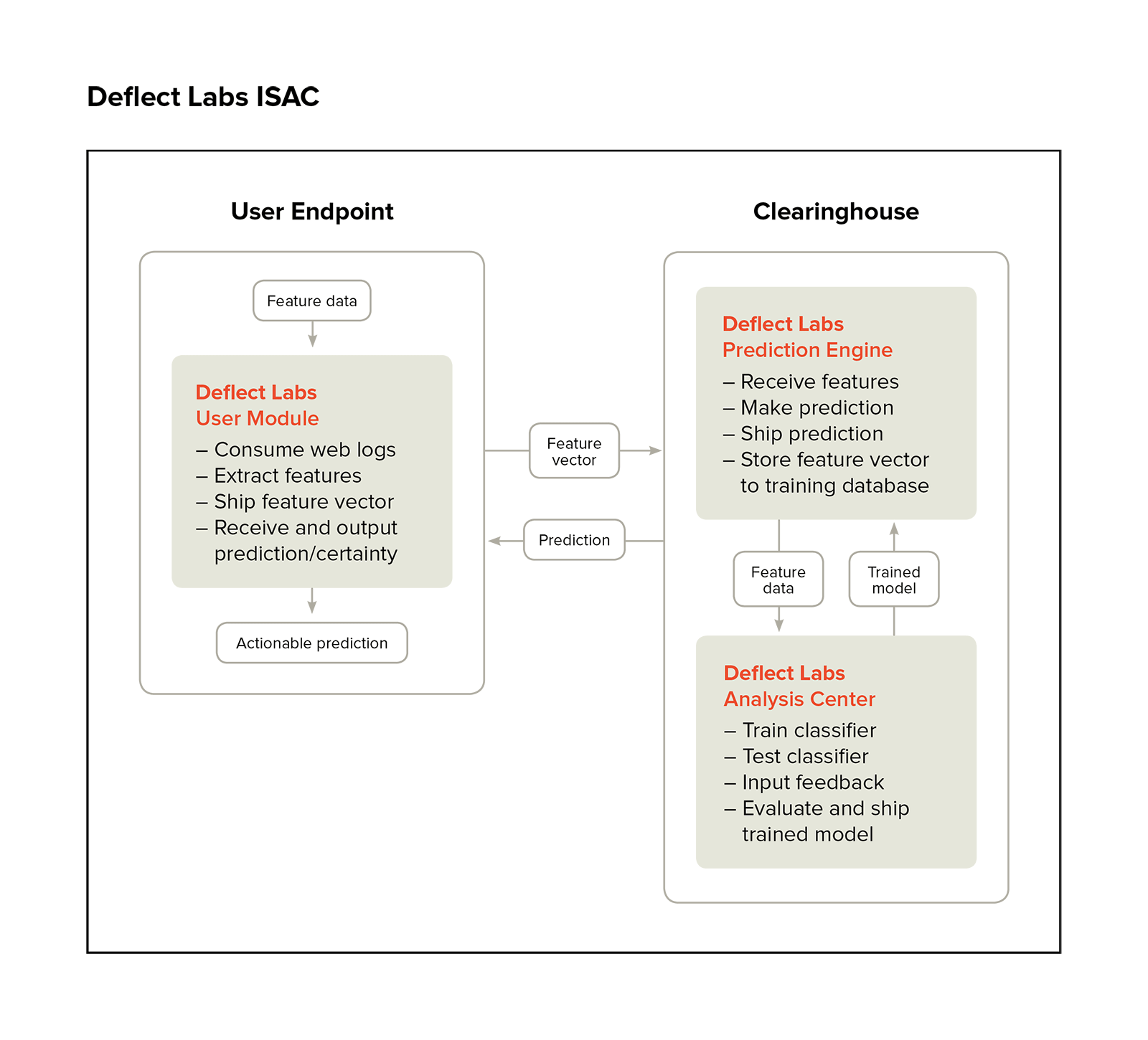
Deflect Labs
eQPress
Ceno
dComms
Ouisync
eQsat
Education
Helpdesks
Conferences
eQTV
Digital Resilience Forum
Ottawa, May 21st 2025